An Exact Symbolic Reduction of Linear Smart Predict+Optimize to Mixed Integer Linear Programming (ICML-22)
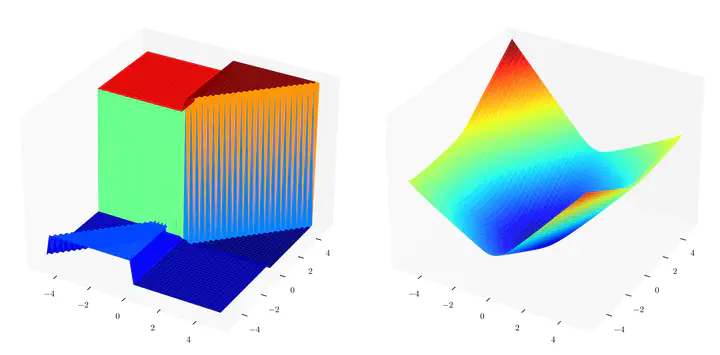 (Left) True SPO loss is piece-wise linear (Right) Convex surrogate SPO+ loss
(Left) True SPO loss is piece-wise linear (Right) Convex surrogate SPO+ lossPredictive models are traditionally optimized independently of their use in downstream decision-based optimization. The `smart, predict then optimize’ (SPO) framework addresses this shortcoming by optimizing predictive models in order to minimize the final downstream decision loss. To date, several local first-order methods and convex approximations have been proposed. These methods have proven to be effective in practice, however, it remains generally unclear as to how close these local solutions are to global optimality. In this paper, we cast the SPO problem as a bi-level program and apply Symbolic Variable Elimination (SVE) to analytically solve the lower optimization. The resulting program can then be formulated as a mixed-integer linear program (MILP) which is solved to global optimality using standard off-the-shelf solvers. To our knowledge, our framework is the first to provide a globally optimal solution to the linear SPO problem. Experimental results comparing with state-of-the-art local SPO solvers show that the globally optimal solution obtains up to two orders of magnitude reduction in decision regret.
Jihwan Jeong
Ph.D. Candidate at University of Toronto
My research interests include offline reinforcement learning, model-based reinforcement learning, decision-aware model learning, meta-learning and Bayesian deep learning.