Biography
Welcome to my profile 😄! I’m a Ph.D. candidate at the University of Toronto, contributing actively to the D3M (Data-Driven Decision-making) lab under the mentorship of Professor Scott Sanner. My interest in AI and ML is rooted in their potential to revolutionize decision-making in diverse areas.
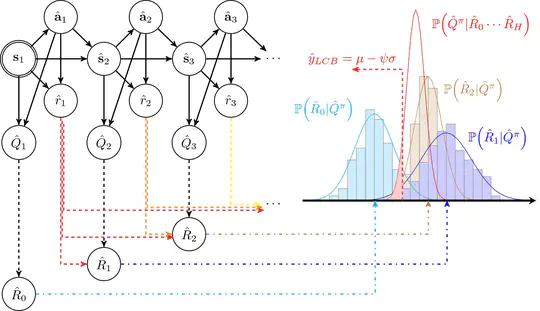
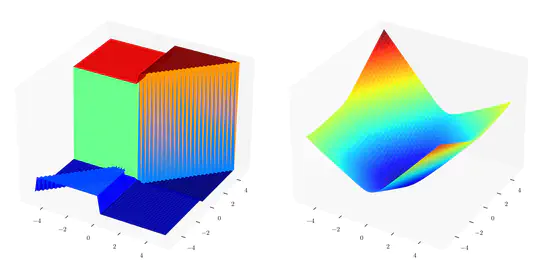
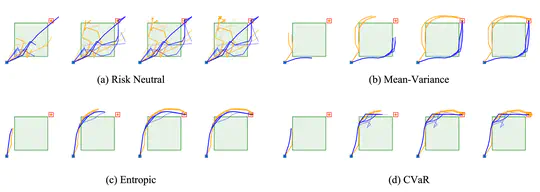
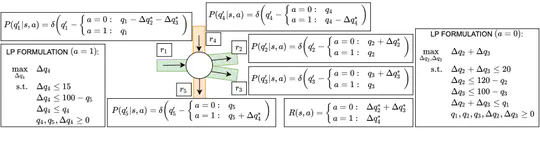
My research primarily focuses on leveraging models for enhanced decision-making, with a special emphasis on offline model-based reinforcement learning. This work includes a notable paper accepted at ICLR-23, which explores the use of Bayesian models for robust planning and policy learning by accounting for the epistemic uncertainty of models (learn more here).
My internship at Google Research, under the guidance of Yinlam Chow, was a transformative period. There, I contributed to integrating recommendation systems with large language models (LLMs), applying Reinforcement Learning with AI Feedback (RLAIF) in a novel way to the challenge of recommendation explanations. This culminated in a first-authored paper that highlights the effective fine-tuning of LLMs for accurate and personalized recommendations. Additionally, I was instrumental in developing the PAX pipeline, a cornerstone for our team’s language model projects. (Check out the other paper here!)
Approaching the completion of my Ph.D., my thesis, tentatively titled “Leveraging Learned Models for Decision-Making,” encapsulates my research ethos. It tackles the intricacies of using imperfect models for decision-making by focusing on (1) optimizing decision loss, (2) employing Bayesian methods for uncertainty management, and (4) enabling models and policies to adapt swiftly in new environments.
I look forward to opportunities that will allow me to apply and expand my expertise in AI/ML, aiming to continue making impactful contributions in this dynamic field.
Download my CV .
- Offline & model-based reinforcement learning
- Uncertainty quantification in neural networks
- RL for Large Language Models
- Decision-aware model learning
Ph.D. Candidate in Information Engineering (Present)
University of Toronto
M.S. in Industrial and Systems Engineering, 2019
Korea Advanced Institute of Science and Technology (KAIST)
B.S. in Chemistry, 2015
Korea Advanced Institute of Science and Technology (KAIST)
Experience
Research Projects

Publications
Teaching Experience
Featured Publications

Gallery





